

데이터 분석 결과를 어떻게 해석할지 수치를 의심해본 적 있으신가요? 데이터 분석 결과를 단순한 평균값만으로 판단하는 것은 굉장히 위험합니다.
아래 기사를 예로 살펴볼까요? 20대 초반 사회초년생의 평균 임금이 200만원이라고 합니다. 과연 이 수치가 올바르다고 말할 수 있을까요? 대다수가 ‘20대 초반 평균 임금이 200만원이라고? 말도 안되는 결과잖아?’라고 생각할 것입니다. 대기업 직원의 평균 임금 또한 7천 920만원이라고 하지만, 정유사 등 제한된 업종에 아니라면 체감 연봉은 그렇게 높지 않을 수 있습니다.
평균이라는 데이터의 함정 유의하기
데이터 분석 또한 마찬가지입니다. 고객의 평균 장바구니 사이즈가 5개라고 하더라도 대다수 사람들이 2~3개를 구매하고 떠날 수 있습니다. 일부 도소매 업자로 보이는 사람들이 수백 수천개의 물건을 구매하는 경우가 있을 수 있죠.
따라서 평균값을 분석할 때는 데이터를 시각화해서 전체 분포를 파악하고 범위 내에서의 데이터를 해석할 수 있어야 합니다.
이 글을 읽고 있는 분들 중에 혹시 취준생 여러분이 있진 않으신가요? 내정된 2개의 기업이 있다고 합시다.
- A기업 : 평균 연령 31세, 평균 연봉 9,000만원
- B기업 : 평균 연령 34세, 평균 연봉 6,000만원
언뜻 보면 A기업이 대다수 사원 연령이 젊고 연봉도 많은 것으로 보입니다. 업종이나 집과의 거리 등을 함께 따져봐야겠지만 단적으로 생각하면 A기업이 훨씬 좋아보이는 것이 사실입니다.
데이터를 쪼개보면 어떨까요?
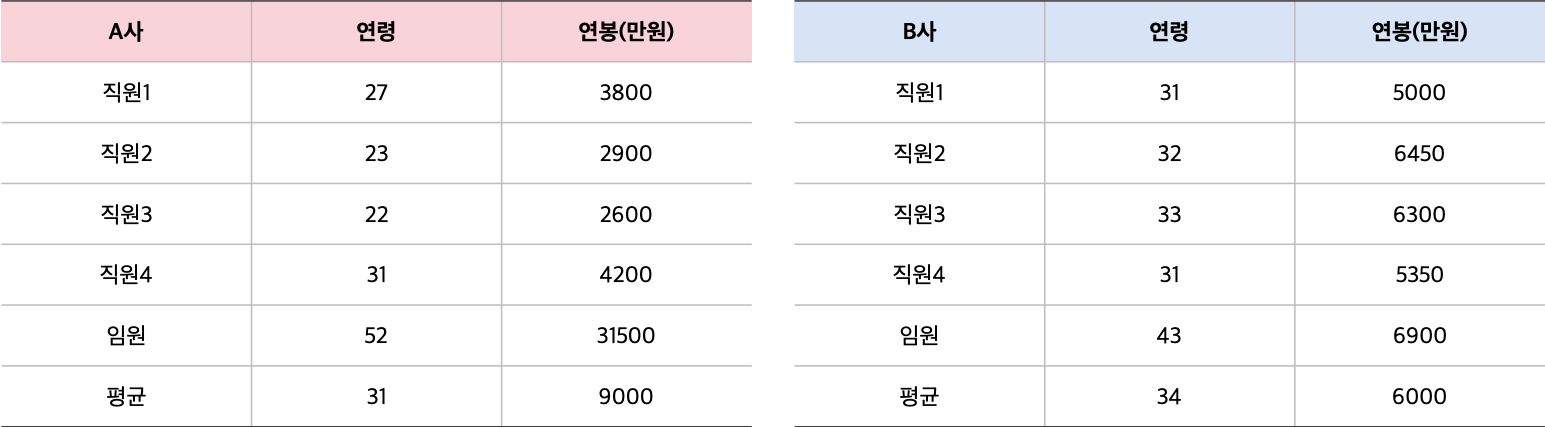
평균은 A사가 훨씬 높지만, 실상은 1명의 임원을 빼면 대다수 20대 초반의 젊은 직원으로 연봉 또한 천차만별이며 임원의 10분의 1에 해당하는 직원도 있습니다.
반면 B사는 전체 직원의 연령 분포가 고르고 평균 임금에도 큰 차이가 없습니다. 평균만으로 판단하기에는 이렇게 해석의 오류가 있을 수 있습니다.
심슨의 역설로 이해하는 통계의 또다른 함정 유의하기
1973년 캘리포니아 주립대학교 버클리 캠퍼스에서는 대학원 입학에서 남자 지원자에게 유리한 결정을 내렸다며 대학이 성차별로 고소를 당한 일이 있었습니다.
공학부와 문학부 전체 남녀 합격률에서 남학생과 여학생간 약 50%에 가까운 현저한 차이가 있었다며 소송을 걸었죠.

그러나 공학부와 문학부를 쪼개 살펴보면 그 수치는 달라집니다. 아래 표를 보듯 공학부와 문학부 모두 여학생의 합격률이 실제론 높았던 것이죠. 이에 캘리포니아 주립대학교에 걸었던 고소가 취하되었습니다.
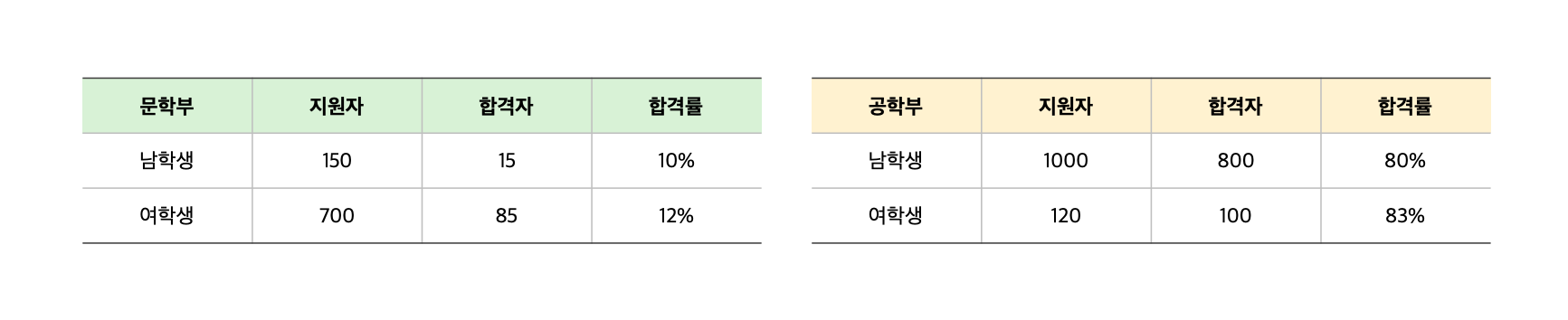
공학부와 문학부 각각 여학생 합격률이 남학생보다 높지만 전체를 보면 남학생 합격률이 높아 ‘상식을 뒤엎는 패러독스’가 발생합니다.
이처럼 부분에서 성립하던 성질이 부분을 합한 전체에선 성립하지 않는 것을 심슨의 역설(Simpson’s Paradox)라고 부릅니다.
실무사례로 심슨의 역설 알아보기!
실무 사례를 가지고 데이터를 분석해 보겠습니다. 분기별 DAU와 객단가를 그래프로 시각화하였습니다.
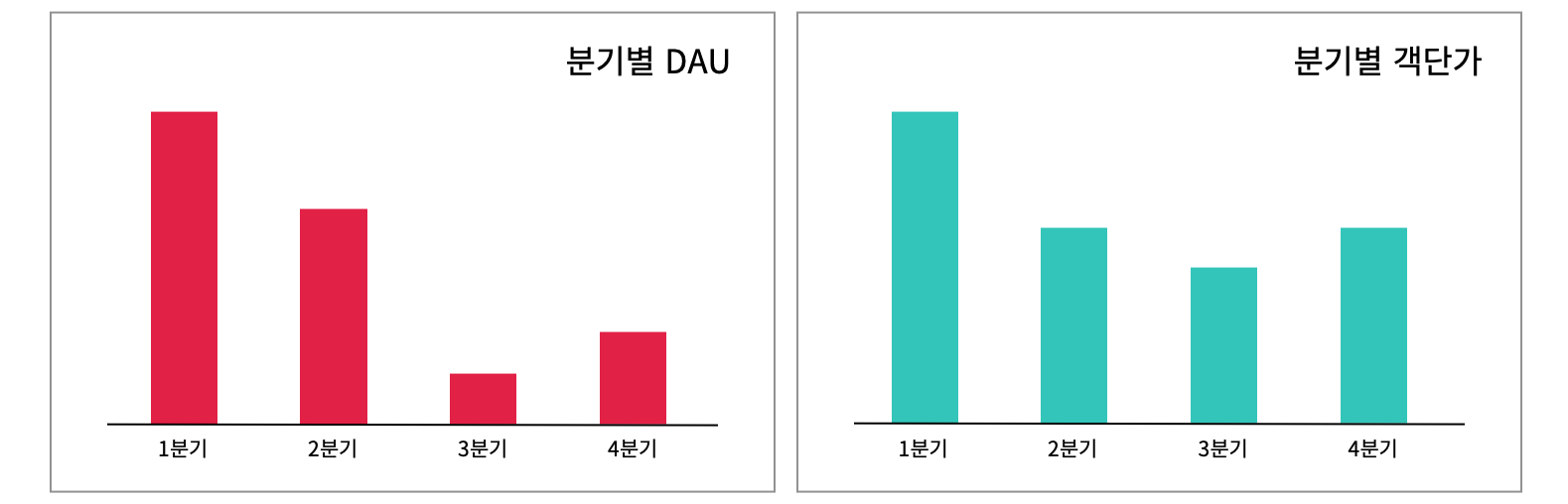
위 그래프를 단순히 살펴보면 1분기를 제외하고 전반적으로 DAU가 크게 줄어들었으며 객단가 또한 하향 추세인 것을 알 수 있습니다.
하지만 데이터를 세분화면 이야기는 달라집니다.
회원가입 고객의 DAU와 객단가 추세가 대동소이하며 4분기에는 2분기와 3분기에 비해 조금씩 올랐습니다.
반면, 비회원가입 고객은 1분기와 2분기 엄청난 DAU와 객단가를 기록했지만 3분기와 4분기 모두 굉장히 수치가 저조하였습니다.
서비스에 지속적으로 도움을 주고 커뮤니케이션이 가능한 회원가입 고객의 동향에는 큰 이슈가 없습니다.
반면 회원가입을 하지 않은 고객의 트렌드가 1분기와 2분기에 갑자기 튀어 전체 평균 데이터에 영향을 준 것을 알 수 있습니다. 체리피커라고도 볼 수 있는 비회원가입 고객이 1분기와 2분기에 특정 상품을 구매하기 위해 잠깐 유입한 것은 아닌지 마케팅팀과 함께 확인하는 것이 바람직합니다.
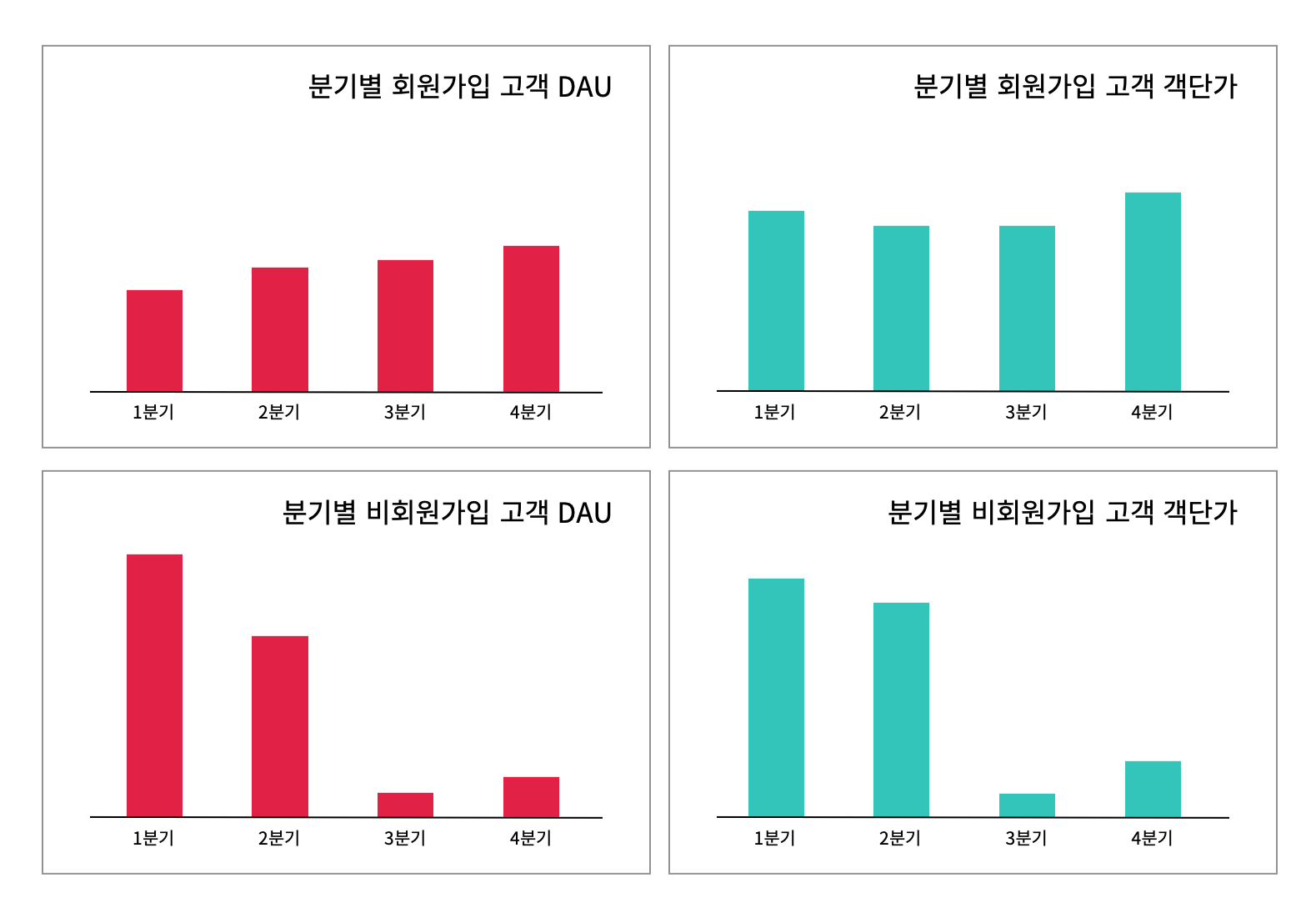
기업의 경영자는 단순 평균 데이터만을 살펴보고 1분기 이후, 계속해서 고객의 접속자 수와 객단가가 하락하여 위기라고 판단하기 쉽습니다.
그러나 세부 데이터는 그렇지 않다는 것을 안다면, 보다 올바른 의사결정을 할 수 있게 됩니다.
심슨의 역설을 피하려면 군집별로 데이터를 ‘쪼개보고’, 쪼갠 데이터를 함께 비교하여 ‘교차분석’하는 것이 가장 중요합니다.
통계의 함정을 잡아내어 올바른 의사결정을 도와주는 뷰저블
뷰저블에서는 이러한 통계의 함정을 잡아내기 위해 타사에서는 제공하지 않는 다양한 세그먼트 기능을 제공합니다.
숨어있는 변수(Lurk Variable)까지 잡아 전체 평균 즉, 통계적 착시만을 가지고 잘못된 의사결정을 내리지 않도록 도와주고 있죠.
광고를 통해 유입된 고객과 그렇지 않은 고객을 구분하여 살펴보거나, Fan’s 그룹과 일반 고객 그룹으로 나누어 Path(대표 행동 흐름)를 보는 것 등을 예로 들 수 있습니다.
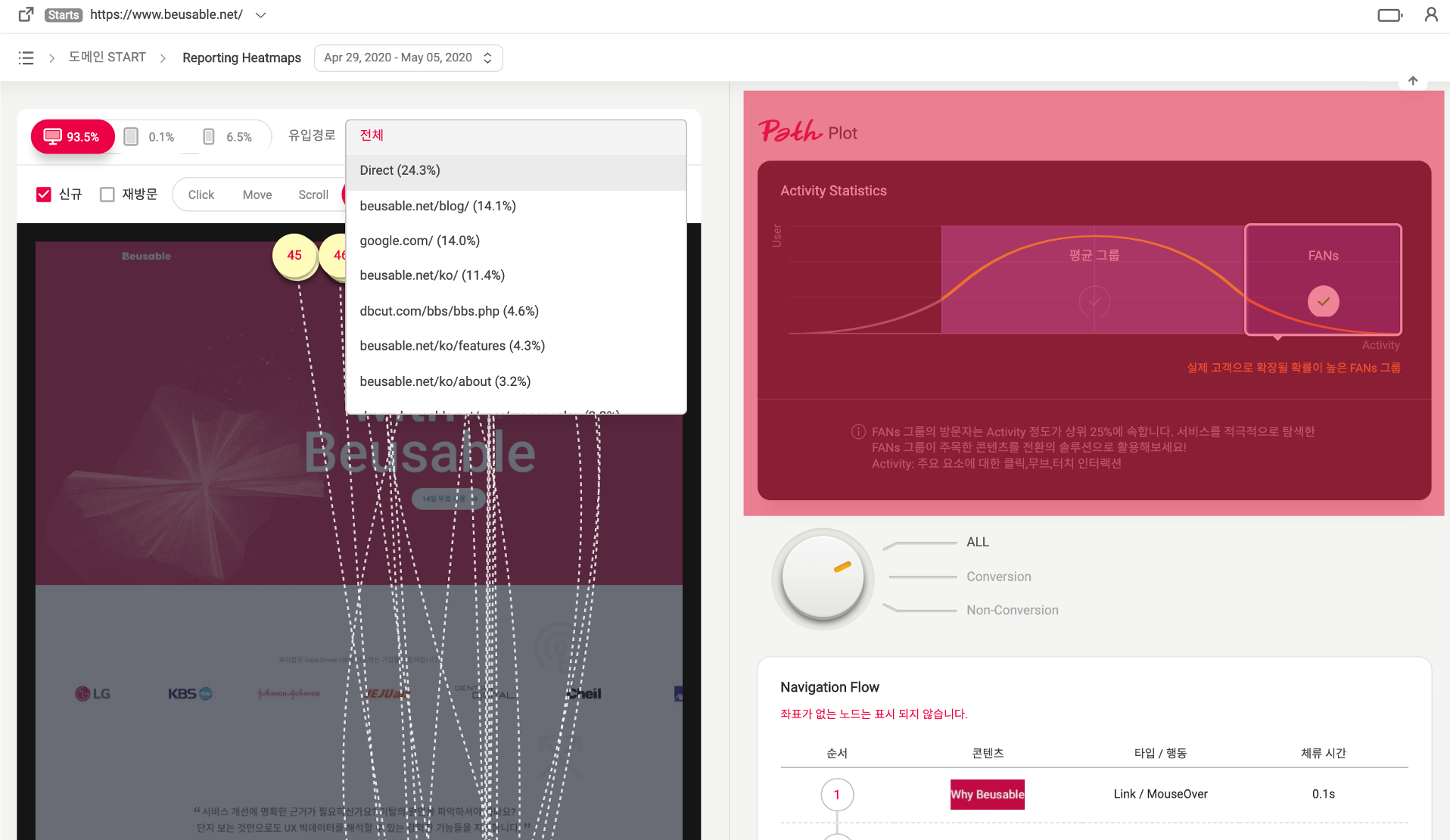
위 이미지에서 빨갛게 표시한 영역은 Path Plot의 세그먼트 기능입니다.
아래처럼 각각 클릭하여 살펴보면 평균적인 활동 범위를 가진 그룹과 실제 고객으로 확장될 확률이 높은 FAN’s 그룹으로 구분됩니다.
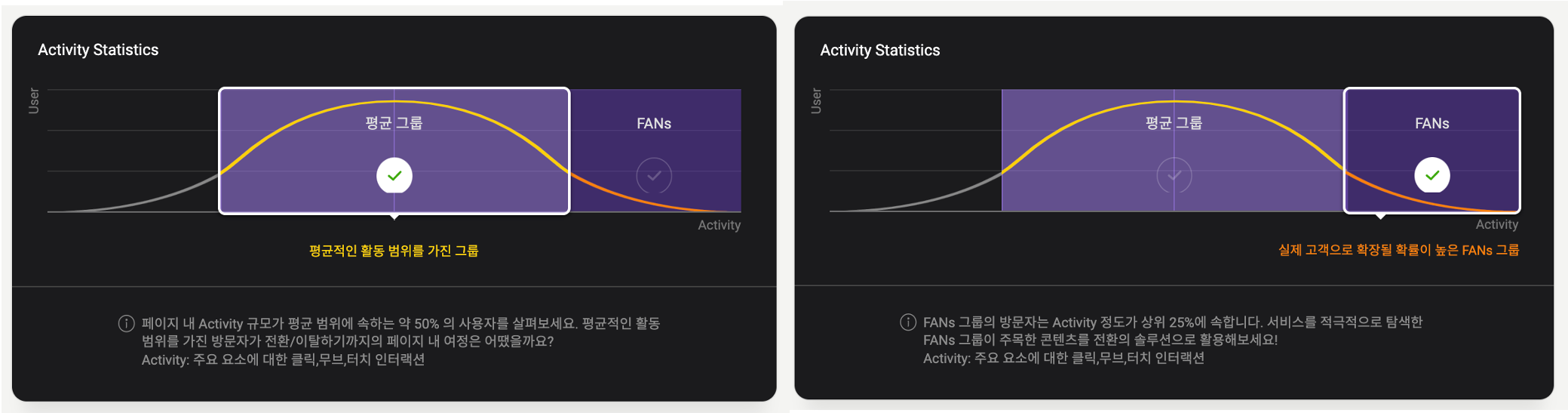
기업 내부 서비스라 광고유입 등으로 세그먼트를 구분할 수 없더라도 행동분포에 따라 구분하여 분석할 수도 있습니다.
- 평균 그룹 : 페이지 내 활동 규모가 평균 범위에 속하는 50% 고객
- FAN’s 그룹 : 페이지 내 활동 규모가 상위 20%에 속하는 고객
뷰저블에서는 이 기능을 페이지 개선의 우선순위를 결정하거나 콘텐츠 타깃을 잡을 때 자주 활용하고 있습니다. 기업에서도 전체 페이지 내 UI/UX를 개편하는 것은 공수가 너무 많이 들기 때문에 우선순위를 정하고 싶을 것입니다.
이 때 평균 고객의 전반적인 행동인지, 진성 고객이 정말 선호하는 콘텐츠 유형은 무엇인지 등을 가려서 판단할 수 있습니다.
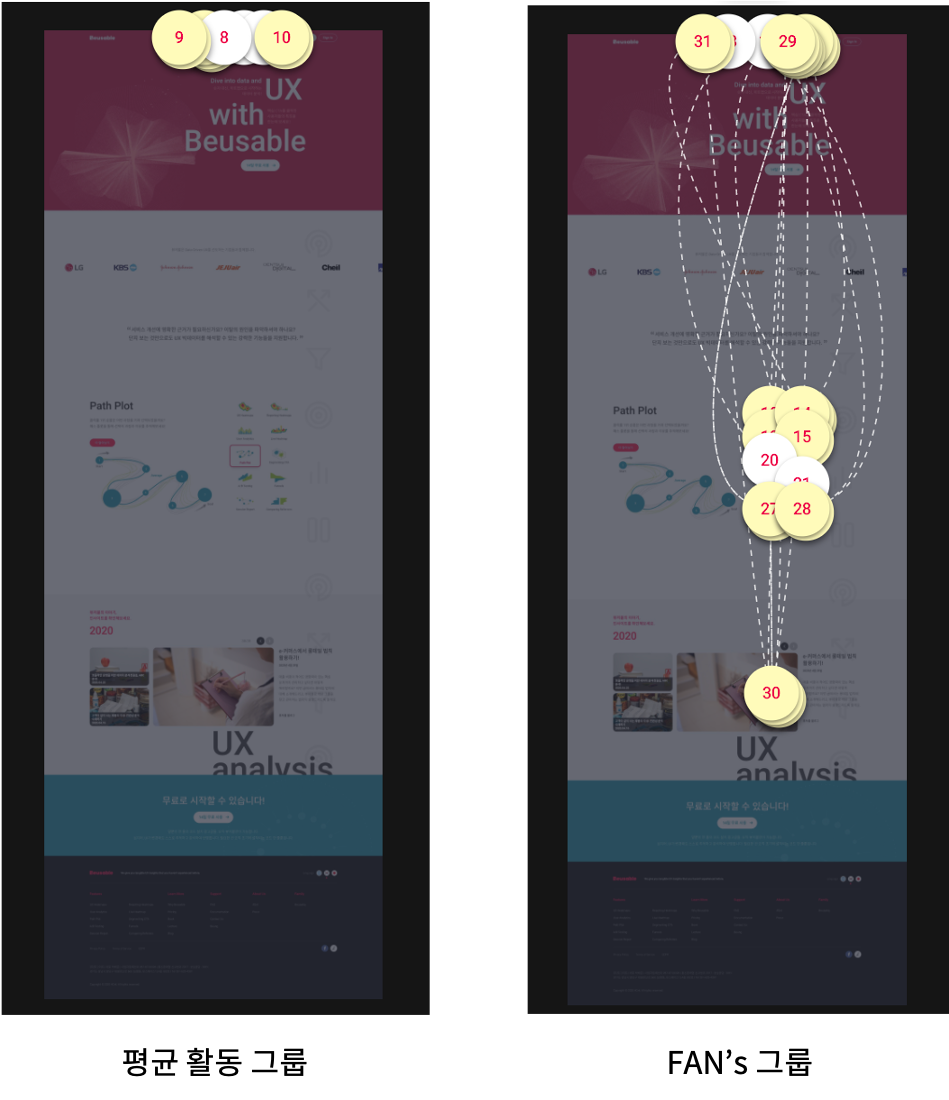
Path를 살펴보겠습니다. 위 그래프를 보면 뷰저블을 이용하는 고객 중 대다수가 GNB 영역을 탐색합니다. 그러나 활동량이 많은 FAN’s 그룹은 하단 블로그 콘텐츠를 주로 탐색하죠.
서비스 기획자와 UX 디자이너는 평균 고객을 대상으로 서비스를 개편할 것인지, 일부 활동량이 많은 고객을 대상으로 개편할 것인지를 결정한 뒤 콘텐츠 개편에 돌입했습니다.
Path-plot으로 개편하기!
먼저 우선순위 1순위로 평균 고객을 위해 개선 목표를 GNB로 잡았습니다. GNB 메뉴명을 더욱 돋보이게 하고 계층 구조로 구성해 고객의 탐색 경험을 더욱 강화하였습니다.
시간이 지나 뷰저블은 2순위 개편에 돌입했습니다. 진짜 뷰저블에 애정을 갖고 콘텐츠를 둘러보려는 FAN’s 고객을 위한 콘텐츠 전환 전략도 새로 구상한 것이죠.
FAN’s 그룹이 많이 탐색하는 세부 요소에도 전환(Conversion)을 위한 트리거들을 마련해두었는데요, Path로 세부 데이터를 살펴보았을 때 블로그 콘텐츠에 특히 체류시간이 높고 중복 탐색 순차가 잡힌 것을 알 수 있습니다. 이 블로그 콘텐츠를 본 고객이 회원가입으로 바로 이어질 수 있도록 기존 브런치로 이동하던 신규 메뉴를 만들어 내부 도메인으로 전환할 수 있게 변경하였습니다.
아무래도 브런치(외부 사이트)로 이동하면 다시 뷰저블 홈페이지로 들어오기까지 상당한 여정과 노력이 들지만, 계속해서 뷰저블 홈페이지에서 콘텐츠를 읽는다면 쉽게 회원가입으로 유도할 수 있는 전략들을 구상할 수 있기 때문입니다. 블로그의 목록은 물론이고 상세 콘텐츠 최하단에 바로 ‘14일 무료 사용’ 이라는 회원가입 버튼을 두었습니다.
[내부 도메인 블로그와 브런치 도메인에서의 고객 회원가입 여정]
- 내부 도메인에서 블로그 콘텐츠를 읽은 고객 또는 블로그 콘텐츠 탐색 과정에서 지속적으로 회원가입 버튼에 노출되어 쉽게 전환할 수 있음
- 브런치를 다 읽은 후 뷰저블 홈페이지 URL을 클릭하지 않으면 회원가입으로 전환할 수 없으며 [뷰저블 URL 클릭 – 회원가입 버튼 위치 탐색 – 회원가입 버튼 클릭]이라는 긴 여정이 필요함
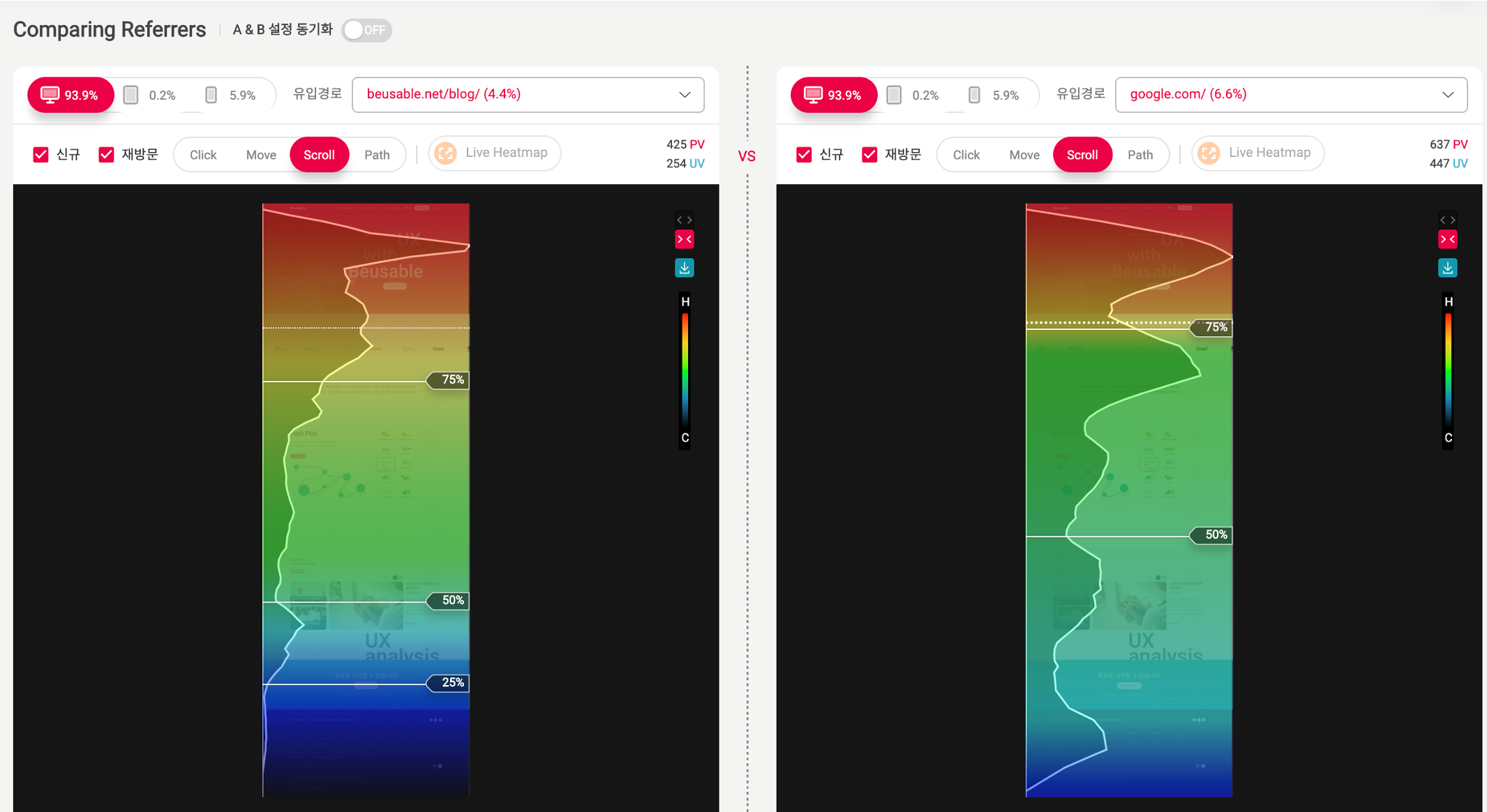
교차분석을 할 때는 Comparing Referrers 기능을 활용할 것을 추천합니다.
여러 개의 히트맵을 캡쳐하거나 저장하여 나열하지 않아도 쉽게 비교할 수 있습니다. 한 화면에서 빠른 분석이 가능하니 편리하죠?
심슨의 역설은 각 부분에 대한 평균이 크다고 해서 전체에 대한 평균까지 크지는 않다는 것을 의미합니다. 영국의 통계학자 에드워드 심슨이 정리한 역설로, 각각의 변수에 신경 쓰지 않고 전체 통계 결과를 유추하다 일어나는 오류에 유의할 것을 말합니다.
뷰저블에서는 데이터를 해석할 때 잘못된 의사결정을 피하고 목적을 명확히 구분하기 위해서 타사에서는 제공하지 않는 다양한 세그먼트 기능들을 제공합니다!
참고 : https://cba.snu.ac.kr/ko/sblcolumn?mode=view&bbsidx=77842





