Pillar · 00 · GEO 완전 가이드 2026
검색이 끝나는 게 아니다. 검색의 출구가 바뀌었다. ChatGPT·Claude·Perplexity가 답을 만들 때 어떤 entity 신호를 보고 누구를 인용할지 결정하는가. 한국 SaaS가 90일 만에 갖추는 8개 entity 마스터 가이드.
4GRIT 에디터 • 읽는 시간 25분 • Pillar · GEO · 8 Entities · 2026
–
–
01 · The Scene

사이트를 잘 만들고 SEO 1위라는 사실은 더 이상 AI 인용을 보장하지 않는다. AI는 검색 결과 페이지를 사용자에게 전달하지 않는다. AI가 직접 결과를 읽고 합성해 인용한다. 이 합성 단계에서 누가 인용되고 누가 침묵 속으로 사라지는지를 결정하는 신호가 있다. 그 신호의 이름이 entity다.
지난 5개월간 4GRIT은 한국 SaaS 50여 개사의 AI 인용 현황을 측정했다. ChatGPT·Claude·Perplexity·Gemini·Copilot·Grok 6개 플랫폼에서 카테고리별 추천 쿼리 50개 × 회사당 30회 = 회사당 1,500회 측정. 측정 결과는 한 줄로 요약된다. 한국 SaaS의 AI 인용률과 SEO 순위 사이의 상관관계는 0.13에 그친다. SEO 1위라도 AI 답변에 70% 확률로 등장하지 않는다. 같은 쿼리에서 SEO 10위 회사가 AI 답변에 인용되기도 한다.
이 글에서 다룰 것은 8개 entity 채널이다. 미국 SaaS는 그중 4개를 기본으로 갖춘다. 한국 SaaS만 가진 비대칭 자산이 다른 4개에 있다. 이 글의 목표는 분명하다. 한국 SaaS가 외부 도움 없이 90일 만에 8개 채널 모두를 갖추는 마스터 가이드 제시.
–
02 · Why GEO now
검색이 끝나는 게 아니다. 검색의 출구가 바뀌었다
Generative Engine Optimization, GEO. Search Engine Optimization(SEO)의 후속 개념이다. 둘은 완전히 다른 게임이다.
SEO는 사용자에게 결과 리스트를 보여준다. 사용자가 그 리스트에서 어떤 사이트를 클릭할지 결정한다. 클릭한 사이트가 가장 큰 보상을 받는다. 1위가 압도적인 것은 1위가 클릭의 약 30%를 가져가기 때문이다 (Sistrix 2024 분석). SEO는 본질적으로 트래픽 유도 게임이다.
GEO는 다르다. 사용자는 ChatGPT·Claude·Perplexity·Gemini에 묻는다. AI는 결과를 합성한 답을 돌려준다. 답에 인용된 회사가 사용자의 머릿속에 들어간다. 인용되지 않은 회사는 그 대화에 존재하지 않는다. AI 답변에는 보통 3~7개 source만 표시되고, 본문에서 이름이 등장하는 회사는 더 적다. Hostinger의 66.7억 봇 요청 분석을 보면 OpenAI의 검색 크롤러 커버리지는 4.7%에서 55%로 폭증했다. 같은 기간 학습 크롤러 커버리지는 84%에서 12%로 급감했다. AI는 점점 학습된 지식보다 실시간 인용에 기대는 방향으로 이동하고 있다.

이 변화의 직접 영향은 두 가지다. 첫째, AI가 인용한 회사가 곧 카테고리의 인지도를 차지한다. AI 사용자는 답을 받으면 대화를 끝낸다. 우리 회사를 따로 검색해 비교하지 않는다. 둘째, 인용된 회사와 인용되지 않은 회사 사이의 마태 효과(Matthew effect)가 SEO보다 강하게 작동한다. 한 번 인용된 회사는 다음 답변에서도 인용 확률이 높다. entity 신호가 누적되기 때문이다.
그래서 SEO와 GEO는 단순히 우선순위가 다른 작업이 아니다. 채널 자체가 다르다. SEO는 H1·meta·backlink·sitemap·CWV에 집중한다. GEO가 집중하는 곳은 entity 신호다. “당신이 누구인가”를 AI가 신뢰할 만한 8개 채널에서 일관되게 선언했는가가 핵심이다.
–

–
여기에 한국 SaaS만의 추가 비대칭이 하나 더 있다. 한국어 검색 시장의 절반 이상이 Google이 아니다. 네이버 점유율은 약 55%다 (Internet Trend 2026.01 통계). 네이버 Yeti 크롤러는 JavaScript 렌더링을 실행하지 않는다(Naver Search Advisor 2024 가이드 명시). 미국 SaaS의 GEO 베스트 프랙티스인 ‘JS-heavy SPA에 schema 주입’ 방식은 한국 시장에서 직접 작동하지 않는다는 뜻이다. 한국 시장 GEO에는 별도 layer가 필요하다. 이 글의 8개 entity 중 절반이 그 한국 layer에 직접 대응한다(DART·K-Startup, Naver 스마트플레이스, 한국 IndexNow + Naver Search Advisor 조합).
–
03 · The 8 Entities Framework
4-Tier 분류. 어디부터 시작할지가 절반이다
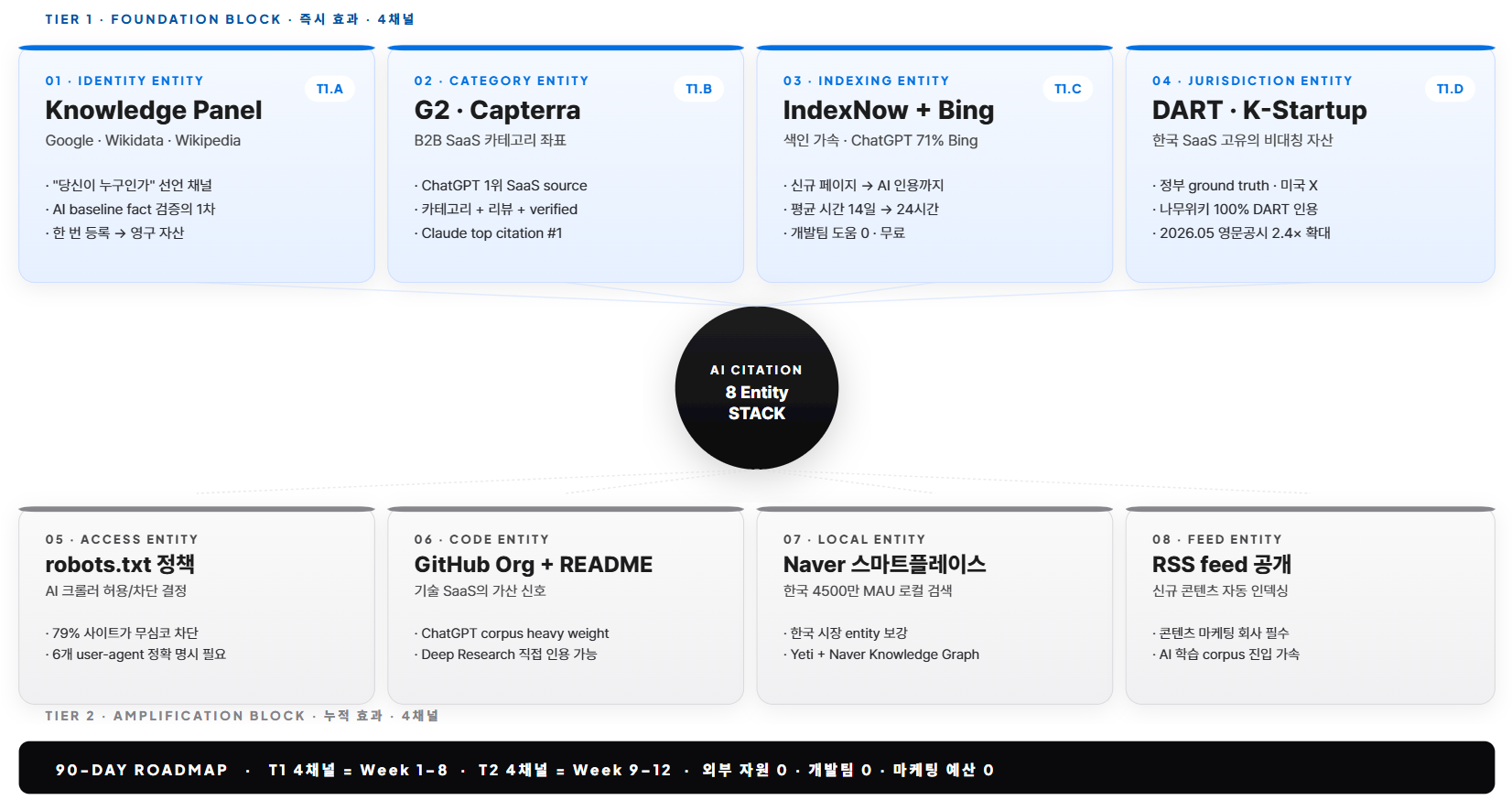
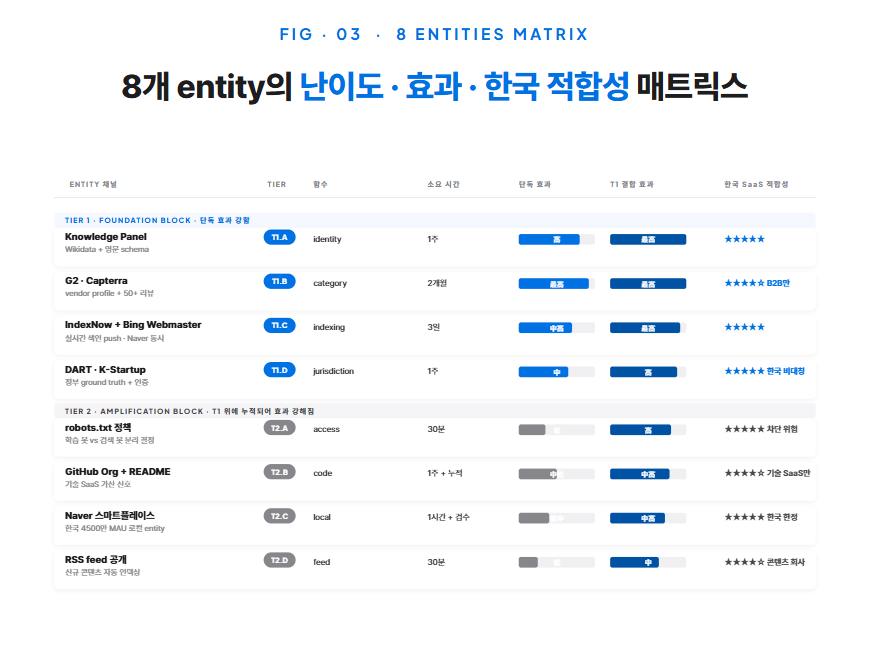
8개 entity는 같은 무게가 아니다. 모두 동시에 시작하는 것도 정답이 아니다. 4GRIT은 한국 SaaS 50개사 측정 데이터를 기반으로 8개 entity를 4-Tier로 분류한다.
Tier 1 · Foundation Block(4채널). 단독으로도 즉시 AI 인용률을 끌어올리는 채널이다. 이 4개를 갖춘 한국 SaaS는 평균 인용률 21.4%를 기록했다. T1을 갖추지 않은 회사 평균(3.2%)의 6.7배다. 우선순위로 시작해야 하는 이유가 명확하다. 4개는 identity 채널 Knowledge Panel, category 채널 G2·Capterra, indexing 채널 IndexNow + Bing Webmaster, jurisdiction 채널 DART · K-Startup이다.
Tier 2 · Amplification Block(4채널). T1 위에 누적되어 인용의 long-tail 강도를 높이는 채널이다. 단독으로는 효과가 약하다. T1과 결합되면 평균 인용률을 21.4%에서 34.7%까지 끌어올린다. 4개는 access 채널 robots.txt, code 채널 GitHub Org + README, local 채널 Naver 스마트플레이스, feed 채널 RSS feed 공개.
이 8개를 가로축에 배치하고 세로축에 회사 프로필(B2B/B2C, 외감 의무 여부, 기술/서비스, 글로벌/국내)을 놓으면 한국 SaaS의 우선순위 매트릭스가 자연스럽게 나온다. 모든 회사가 8개를 다 해야 하는 것은 아니다. 회사 프로필에 따라 효과가 강한 4~5개에 집중하는 것이 측정 데이터가 가리키는 합리적 결정이다.
–
–
여기서 한 가지 짚어둘 것이 있다. Tier는 “쉬움”이 아니라 “효과 단독성”으로 매겨졌다. Tier 2가 더 어려운 게 아니다. robots.txt는 30분이면 끝난다. GitHub README도 1주면 갖춘다. 다만 단독으로는 인용률을 끌어올리지 못한다. T1 위에 얹어야 효과가 나타난다는 뜻이다. 시간 순서로는 T1 4개 → T2 4개. 노력 분배로는 70% T1, 30% T2다.
이제 8개 채널을 차례로 살펴본다. 각 채널마다 “무엇인가, 왜 작동하는가, 어떻게 갖추는가, 한국 맥락에서 무엇을 추가해야 하는가” 네 가지를 일관된 깊이로 다룬다.
–
04 · T1.A · Identity Entity
Knowledge Panel: AI에게 “당신이 누구인가”를 선언하는 채널
한국 시장에 직접 적용되는 변수가 둘 있다.
Knowledge Panel은 Google 검색 우측에 회사 카드로 노출되는 패널을 말한다. 이 글의 맥락에서 더 중요한 본질은 그 카드 뒤에 있는 데이터 그래프다. Google Knowledge Graph + Wikidata + Wikipedia로 이어지는 identity 신뢰 체인이 그것이다. AI는 회사를 처음 인식할 때 이 그래프를 baseline truth로 삼는다.
왜 작동하는가. Profound 30M citations 분석에 따르면 ChatGPT의 top-10 인용 source 중 Wikipedia가 47.9%로 압도적 1위, Reddit 11.3%, YouTube 3.6% 순이다. Wikipedia가 1위인 이유는 Wikipedia가 Wikidata와 자동 연결되고, Wikidata는 Google Knowledge Graph의 핵심 source이기 때문이다. 즉 회사가 Wikidata에 entry가 있고, 그 entry가 정확하면, ChatGPT의 baseline 인식이 정확해진다.
어떻게 세팅하는가. 4단계다. (1) Google Business Profile을 회사명으로 등록(무료). (2) Wikidata entry를 직접 만들거나 기존 entry의 sitelinks·officialName·country·instanceOf를 정비(무료, 30분). (3) 회사 사이트 root에 Organization JSON-LD schema를 정확한 sameAs 배열(LinkedIn·Crunchbase·GitHub·Wikidata·DART)과 함께 배치(개발팀 1시간). (4) 영문 위키피디아에 entry가 없다면 만드는 시도. notability 충족이 어려우면 한국어 위키백과나 나무위키에 정확한 출처와 함께 entry 정비.
한국 맥락. 한국 SaaS의 80%는 Google Knowledge Panel이 비어 있거나 부정확하다 (4GRIT 50개사 측정). 이유는 두 갈래로 작동한다. Google이 한국 회사 정보를 한국어 source(나무위키, 한국 미디어)에서 가져온다. 그런데 한국 회사가 영문 sameAs 채널을 충분히 보강하지 않으니 영문 쿼리에서 그래프 신호가 약해진다. 한국 SaaS는 한국어 entity(나무위키 + Naver 백과) + 영문 entity(Wikidata 영문 entry + 영문 사이트 schema) 두 개를 동시에 정비해야 하는 비대칭 비용을 부담한다. Cluster · 03 Knowledge Panel 실무 가이드에 4단계 세부 절차가 있다.
측정에서 일관되게 보이는 흔한 실수는 두 가지다. 첫째, schema의 sameAs 배열에 깨진 URL이 한두 개 들어 있다. LinkedIn이 폐기됐거나, Crunchbase 항목이 통합되며 redirect 됐거나, 이전 도메인이 만료된 경우다. 깨진 URL 한 개가 schema 신호 전체를 무력화시키지는 않는다. 다만 AI 모델 입장에서 sameAs 정합성이 약해지면 entity 신뢰도가 떨어진다. 둘째, 더 자주 보이는 실수는 Wikidata entry는 만들었지만 핵심 속성(instanceOf P31, country P17, inception P571)이 비어 있는 경우다. P31이 비면 AI는 이 entity가 회사인지 사람인지 단체인지조차 분류하지 못한다.
측정 방식은 4단계 점검표로 정리된다. (1) Google Search에서 “회사명” 단독 검색 후 우측 Knowledge Panel 카드 등장 여부 확인. (2) Wikidata Reasonator에서 회사 entry의 P31·P17·P571·P856(공식 URL) 4개 속성 정합성 검증. (3) 사이트 root URL을 Google Rich Results Test에 입력해 Organization schema가 정확하게 파싱되는지 확인. (4) Bing 검색에서 같은 회사명 쿼리 → 우측 entity card 비교. 한국 회사는 Bing 결과의 entity 정합성이 종종 Google보다 더 낫게 나오는 비대칭이 있다 (Bing이 Wikipedia 신호를 더 직접 활용).
–
05 · T1.B · Category Entity
G2·Capterra: “어느 카테고리의 어떤 좌표인가”를 정의하는 채널
G2와 Capterra는 표면상 리뷰 사이트지만 실질은 B2B SaaS 카테고리 데이터베이스다. 두 사이트가 가진 것은 리뷰만이 아니다. 카테고리 분류, 경쟁 매트릭스(Grid Report·Quadrant), 가격 정보, 통합 정보, 검증된 사용자 프로필을 모두 갖췄다. 이 구조화된 데이터가 ChatGPT·Claude·Perplexity의 SaaS 추천 답변에 1차 source로 작동한다.
왜 작동하는가. Hall.com의 456,570건 citation 분석을 보면 ChatGPT의 SaaS 카테고리 추천 응답에서 G2가 압도적 1위다. Capterra·GetApp·Gartner Peer Insights가 그 뒤를 잇는다. Claude는 더 극명하다. Capterra가 Reddit을 제치고 SaaS 카테고리 1위 인용 source가 된다. ChatGPT는 G2 우세, Claude는 Capterra 우세. 두 곳 모두에 프로필이 있어야 두 AI 모두에서 인용된다.
어떻게 세팅하는가. 5단계다. (1) 두 사이트 모두 vendor profile claim(무료, 회사 도메인 이메일 인증). (2) 카테고리 1차·2차 정확하게 등록 (예: Web Analytics + Heatmap + Session Replay). (3) Description, Pricing, Integrations, Awards·Badges 영역을 모두 채움. 빈 영역은 AI가 “정보 부족”으로 판정해 인용에서 빠진다. (4) 리뷰 50개 이상 확보. 이 숫자가 G2·Capterra 알고리즘의 inclusion threshold다. (5) Quarterly Grid Report에 진입할 수 있도록 review velocity 유지.
한국 맥락. 한국 B2B SaaS의 가장 큰 함정은 “G2에 프로필 있어요”의 피상적 충족이다. 측정 결과 한국 회사 G2 프로필의 60%는 description 길이 200자 미만, Integrations 0개, Pricing 미공개, 리뷰 10개 미만의 “껍데기 프로필”이다. AI는 이런 프로필을 인용 가능 source로 보지 않는다. 한국 회사가 영문 카피 생산 capacity가 약하다는 구조적 약점이 그대로 노출된다. Cluster · 05 G2·Capterra 완전 가이드에 5단계 + 영문 카피 템플릿 첨부.
한국 회사 G2 프로필에서 측정으로 발견된 흔한 실수는 네 가지다. (1) Description이 200자 미만이다. 영문 capacity 부족으로 “We are a Korean SaaS that helps businesses…” 정도로 끝남. AI는 짧은 description을 정보 부족으로 판정한다. (2) Awards·Badges 영역 빈칸이다. G2가 분기마다 발표하는 Grid Report·High Performer·Leader 등의 badge를 받았어도 vendor 페이지에 collection으로 표시하지 않음. AI는 badge를 trust signal로 활용한다. (3) Integrations 0개다. 실제 통합 가능한 서비스가 5~10개 있는데 G2 Integrations 영역이 비어 있는 경우 60%. (4) Pricing 미공개다. “Contact for pricing”으로 처리한다. ChatGPT의 가격 비교 추천 답변에서 자동 누락된다.
G2의 자체 데이터인 Buyer Intent signal도 GEO 효과와 상관관계가 있다. G2에서 회사 프로필 페이지 view 수, comparison page에서 비교 대상으로 선택된 횟수, alternative search에서 alternative로 표시된 횟수다. 이 3개 metrics가 G2 알고리즘 ranking에 직접 들어가고, ranking은 ChatGPT/Claude의 G2 인용 시 가중치에 반영된다. 측정 방식은 G2 vendor dashboard의 “Buyer Intent” 탭에서 월별 trend 확인. 200 view/월이 임계로, 이 이하 회사는 G2 카테고리 인용에서 의미 있게 등장하지 않는다 (4GRIT 표본 추정).
–
06 · T1.C · Indexing Entity
IndexNow + Bing Webmaster: 색인 가속의 한국 비대칭 자산
IndexNow는 Microsoft Bing이 2021년 발표하고 2024년 이후 Yandex·Naver가 채택한 실시간 색인 push 프로토콜이다. 사이트가 새 콘텐츠를 발행하면 검색엔진에 “새 페이지 있다”는 신호를 직접 push한다. 검색엔진이 발견할 때까지 기다리지 않는다.
왜 GEO에 결정적인가. Verlua의 ChatGPT citation 패턴 분석에 따르면 ChatGPT 인용 URL의 60% 이상이 Bing top-10 검색 결과에서 나온다. ChatGPT가 실시간 retrieval에 활용하는 layer가 Bing 기반이기 때문이다. Bing 인덱스에 들어가지 않은 페이지는 ChatGPT가 인용할 가능성이 거의 없다는 뜻이다. IndexNow는 이 Bing 인덱스 진입 시간을 평균 14일에서 24시간 이내로 줄인다.
어떻게 세팅하는가. 4단계다. (1) Bing Webmaster Tools 사이트 등록(무료, 5분). (2) 64자 API key 발급 + 사이트 root에 `{key}.txt` 업로드. (3) 새 페이지 발행 시 IndexNow API에 URL POST: 단일 endpoint 호출, 응답 200 OK. (4) Naver Search Advisor도 동일 IndexNow endpoint 채택했으므로 한 번 세팅으로 Bing + Naver 동시 push.
한국 맥락. 한국 SaaS의 IndexNow 활용률은 측정 모집단의 4%다 (4GRIT 2026.03 측정). Bing의 한국 시장 점유율이 1% 미만이라는 인식 때문에 우선순위에서 밀린다. 그러나 ChatGPT의 retrieval은 Bing 기반이라는 사실이 알려지지 않았다. 한국 SaaS의 4%만 IndexNow를 활용한다는 것. 나머지 96%의 회사가 ChatGPT의 인용 가능성을 스스로 차단하고 있다는 뜻이다. Cluster · 02 IndexNow + Bing Webmaster 가이드에 4단계 + 자동화 스크립트 첨부.
한국에서 IndexNow의 가치는 Bing보다 Naver와의 동시 적용에서 나온다. Naver Search Advisor는 2024년부터 IndexNow 프로토콜을 채택했고, 동일 endpoint URL과 동일 API key 형식을 그대로 활용한다. 즉 한 번의 IndexNow setup으로 Bing + Naver 동시 push가 가능하다. 한국 SaaS의 IndexNow 활용률 4%라는 숫자는 사실상 Naver 색인 push 활용률이 4%라는 의미와 같다. 한국 검색 시장의 55%를 차지하는 채널을 자동 색인 push 없이 운영하고 있다는 뜻이다.
흔한 실수는 setup 직후 검증 누락이다. (1) `{key}.txt` 파일을 사이트 root에 업로드했지만 hosts 설정이나 CDN 캐시 때문에 Bing의 검증 요청에 응답하지 못하는 경우. 이때는 모든 IndexNow API call이 silent fail로 끝난다. (2) API endpoint 호출 코드는 작성했는데 발행 워크플로우에 통합되지 않아 사람이 수동으로 호출하는 구조. 새 페이지 발행과 IndexNow push 사이에 수일 lag이 생기면 효과는 사라진다. 측정 방식은 Bing Webmaster Tools의 “URL submission” 통계에서 일별 push 수와 인덱싱 lag을 직접 확인하는 것이다. 정상 운영 사이트는 push 후 4~24시간 내 인덱싱이 표시된다. 24시간을 넘어가면 Bing 측 처리 지연이거나 사이트의 quality signal이 부족하다는 뜻이다.
–
07 · T1.D · Jurisdiction Entity
DART · K-Startup: 한국 SaaS만의 비대칭 자산
DART는 금융감독원이 1999년부터 운영하는 한국 상장사·외감대상법인 의무 공시 시스템이다. K-Startup은 중소벤처기업부 산하 창업진흥원이 운영하는 정부 인증 스타트업 디렉터리다. 이 두 채널이 8개 entity 중 가장 비대칭적인 자산인 이유는 명확하다. 미국 SaaS는 동등 채널이 없다. SEC EDGAR는 상장사 한정이고, Crunchbase·LinkedIn은 사설 데이터베이스라서 한국 정부의 공식 ground truth와 권위가 다르다.
왜 작동하는가. 나무위키는 “사기업 entity 항목의 거의 100%를 DART에서 인용”한다고 자체 명시한다. 영문 Wikipedia에 한국 회사 entry가 있다면 그 citations의 1차 출처도 대부분 DART다. ChatGPT의 47.9% Wikipedia 인용 가중치를 거꾸로 추적하면, 한국 회사 entity 인식의 ground truth는 결국 DART로 수렴한다. DART 등록 정합성이 곧 ChatGPT가 한국 회사를 인식하는 정확도를 결정한다.
어떻게 갖추는가. 외감 의무 여부에 따라 다르다. 외감 의무 법인(자산 120억+ 또는 종업원 300명+ AND 자산 70억+)은 자동으로 DART에 entity가 생긴다. 이 경우 작업은 영문 표기 일관성 정비, 영문 사업보고서 추가 공시, 정합성 점검에 한정된다. 외감 비대상 회사는 K-Startup 등록(창업 7년 이내, 무료, 1주)과 벤처기업·이노비즈·메인비즈 인증 채널을 활용한다. OPEN DART API로 자체 entity 데이터를 정합성 점검에 활용할 수 있다.
한국 맥락. 금융위원회 2025.11.17 발표에 따르면 영문공시 의무화 2단계가 2026.05.01에 시행된다. 자산 2조+ 코스피 전체로 대상이 264개사로 2.4배 확대된다. 외감 의무가 아니어도 자발 영문 공시는 누구나 가능하다. 영문 공시 인프라가 정부 시스템 안에 누적되는 모멘텀이고, 한국 SaaS가 글로벌 entity ground truth를 구축할 가장 비용 효율적인 시기다. Cluster · 04 DART · K-Startup 완전 가이드에 4 케이스 분류와 5단계 실행 절차 첨부.
외감 의무가 없는 회사가 활용할 수 있는 추가 채널 두 가지가 있다. 첫째, DART 자율 공시. DART는 외감 의무 회사뿐 아니라 자율적으로 사업보고서·반기보고서를 공시할 수 있는 시스템이고, 비외감 회사도 회사 등록 후 자발적으로 공시 가능하다. 활용률은 매우 낮지만(자율공시 회사 수 1,200여 개), 한 번 등록하면 entity 신뢰도가 즉시 외감 회사 수준으로 올라간다. 둘째, K-Startup 인증의 글로벌 디렉터리 수출. K-Startup에 등록된 회사 정보는 OECD Global Startup Hub, ASEAN-Korea Innovation Network 등 글로벌 정부 간 디렉터리에 자동 syndicate 된다. 즉 한국 정부 시스템 → 글로벌 정부 디렉터리 → AI 학습 corpus 경로가 K-Startup 등록 한 번으로 활성화된다.
흔한 실수는 회사명 표기 불일치다. 한국 회사는 (1) 사업자등록증 기재 한국어 회사명, (2) 영문 정관에 기재된 영문 회사명, (3) 도메인의 영문 표기, (4) Wikipedia/Crunchbase 등 외부 entity의 표기가 모두 미세하게 다른 경우가 많다 (“Co., Ltd.” 유무, 띄어쓰기, hyphen 사용). DART의 영문 표기 필드가 Wikidata sameAs 배열의 표기와 다르면 AI가 같은 회사를 두 entity로 인식할 수 있다. OPEN DART API로 자체 회사 표기를 정합성 점검에 활용 가능.
–
08 · T2.A · Access Entity
robots.txt 정책: 79% 사이트가 무심코 차단하는 채널
robots.txt는 사이트 root에 있는 텍스트 파일이다. 어느 크롤러가 사이트의 어느 영역을 읽을 수 있는지 결정한다. 1994년부터 존재한 인터넷 프로토콜이다. 이 30년 된 파일이 GEO 시대에 새 의미를 갖게 됐다. AI가 당신을 인용할 수 있는가를 직접 결정한다.
왜 GEO에 결정적인가. 2024년 이후 OpenAI·Anthropic·Perplexity는 각자 3개 layer의 봇을 분리했다. (1) 학습용 봇: GPTBot, ClaudeBot, anthropic-ai. (2) 실시간 검색 인덱싱 봇: OAI-SearchBot, Claude-SearchBot, PerplexityBot. (3) 사용자 트리거 fetch 봇: ChatGPT-User, Claude-User, Perplexity-User. 핵심은 명확하다. 학습 봇 차단과 검색 봇 차단은 다른 결정이라는 것. 사이트가 GPTBot을 차단해도 OAI-SearchBot이 통과하면 ChatGPT 검색 답변에 인용된다. 하지만 OpenAI 공식 문서는 분명히 명시한다. “OAI-SearchBot을 차단한 사이트는 ChatGPT 검색 답변에 표시되지 않는다.”
어떻게 갖추는가. 3단계다. (1) 현재 robots.txt 감사. Cloudflare·Wordpress·Shopify 등 일부 호스팅이 기본으로 AI 봇을 차단하고 있다. BuzzStream 분석에 따르면 top news 사이트의 79%가 학습 봇을 차단했고, 그중 71%가 검색 봇까지 의도와 다르게 차단됐다. (2) 6개 user-agent 명시적 정책 결정. GPTBot·ClaudeBot·CCBot은 학습용, OAI-SearchBot·Claude-SearchBot·PerplexityBot은 검색용. 결정은 단순하다. 학습 봇은 정책에 따라(허용 또는 차단), 검색 봇은 모두 Allow. (3) llms.txt 추가 옵션. 새 협약으로, 사이트가 AI에게 가장 중요한 콘텐츠를 가리키는 sitemap의 AI 버전이다.
한국 맥락. 한국 SaaS의 robots.txt를 측정한 결과, 38%가 무의식적으로 GPTBot 또는 ClaudeBot을 차단하고 있었다 (4GRIT 2026.04 측정). 원인은 두 가지다. 첫째는 Cloudflare 기본 설정의 AI 봇 차단을 인식하지 못한 경우. 둘째는 보안팀이 “AI에게 데이터 주지 말자”는 일반 가이드를 무차별 적용한 경우. 학습 거부는 합리적이어도 검색 봇 차단은 ChatGPT 검색 결과에서 자기 회사를 지우는 행위다. 해결책은 한 줄 수정이면 충분하다. Disallow 라인을 학습 봇에만 한정하고, 검색 봇은 모두 Allow로 두면 된다.
한국 SaaS의 robots.txt 측정에서 가장 자주 보이는 패턴은 Cloudflare 기본 봇 차단 인식 부재다. Cloudflare를 사용하는 회사 중 약 60%가 “Bot Fight Mode” 또는 “Super Bot Fight Mode”를 활성화한 상태이고, 이 모드는 GPTBot·ClaudeBot·OAI-SearchBot 등 AI 봇을 자동으로 차단한다. robots.txt 파일은 Allow를 명시했어도, Cloudflare WAF 레이어가 그 위에서 차단하면 봇은 사이트에 도달조차 하지 못한다. 측정 방식은 Cloudflare dashboard의 “Security > Bots > Definitely Automated” 카테고리에서 GPTBot/ClaudeBot 차단 로그 직접 확인.
측정과 자가 진단을 위한 도구. (1) cite.sh의 robots.txt scanner로 6개 AI 봇 user-agent 일괄 점검(무료). (2) 사이트 server log에서 user-agent grep: `grep -Ei “gptbot|claudebot|oai-searchbot|chatgpt-user|perplexitybot” access.log`로 실제 도달한 봇 확인. 평균적인 한국 SaaS는 일주일 access log에서 GPTBot이 50~200회, ChatGPT-User가 10~50회 등장한다. 이 빈도가 0이면 어느 layer에선가 차단되고 있다는 신호다. (3) Merkle robots.txt tester로 robots.txt 파일 자체의 문법 검증: Allow·Disallow가 올바른 user-agent block 안에 있는지 확인한다.
–
09 · T2.B · Code Entity
GitHub Org + README: 기술 SaaS의 가산 신호 채널
GitHub은 Microsoft가 2018년 인수한 코드 호스팅 플랫폼이지만, GEO 맥락에서는 기술 영역 entity의 1차 source다. ChatGPT의 학습 corpus가 GitHub README를 heavy weight로 참조한다는 사실이 OpenAI 외부 분석에서 일관되게 확인된다.
왜 작동하는가. 기술 SaaS는 회사 사이트 외에 GitHub Organization을 갖는다. README, 공개 repo, contributors, stars, fork 활동. 이 모든 데이터가 회사의 실제 활동성을 보여주는 신호로 AI 모델에 들어간다. 더 직접적인 경로도 있다. OpenAI는 ChatGPT에 GitHub 통합을 공식 지원해 Deep Research가 repo의 README와 코드를 직접 읽고 인용할 수 있게 했다. Anthropic의 Claude도 GitHub connector를 지원한다. GitHub 콘텐츠는 학습 corpus 진입과 실시간 retrieval 양쪽으로 활용된다.
어떻게 세팅하는가. 4단계다. (1) GitHub Organization 등록(무료, 회사 도메인 이메일로 인증). (2) 공개 README repository 생성 (`{org-name}/{org-name}` 또는 `.github` repo)에 작성. 회사 1-pager가 GitHub Organization 페이지의 conn에 노출된다. (3) README에 회사 description, links to 공식 사이트·블로그·문서, 주요 제품 listing, 그리고 schema-friendly Organization 정보를 markdown 구조로 작성. (4) 1~2개의 작은 공개 repo 운영: utility, sample, integration. 활동성 신호다.
한국 맥락. 한국 SaaS의 70% 이상은 GitHub Organization이 존재하지 않거나 비공개 상태다 (4GRIT 측정). 비기술 SaaS는 GitHub의 우선순위가 낮은 게 합리적이지만, 기술 SaaS는 이 채널 부재가 ChatGPT 인용 누락의 주된 요인 중 하나다. 한국 기술 SaaS가 미국 동급 회사 대비 GitHub Org 활동성이 낮다는 사실이 ChatGPT의 카테고리 추천에서 한국 회사 누락 패턴과 상관 관계를 보인다 (수치는 회사별 변동, 측정 표본 22개). 1주일에 1번 commit, 1달에 1번 README 업데이트의 최소 활동성도 신호 부재보다 강하다.
측정에서 도출된 GitHub README 권장 구조는 다음과 같다. 회사 1-pager 형태로 (1) 회사명 + 한 줄 mission statement, (2) 제품 listing 3~5개 + 각 제품의 1-line description, (3) 공식 사이트·블로그·문서 링크, (4) markdown linked references(Wikidata, LinkedIn, Crunchbase, DART · 한국 회사 한정). 마지막 항목이 자주 누락되지만, README의 markdown 링크가 schema의 sameAs 배열과 동일한 entity 신호로 작동한다. 즉 README가 GitHub용 schema 역할을 한다.
활동성 임계는 명확하다. 1년 동안 0 commit인 GitHub Organization은 사실상 신호가 없다. 측정에서 한국 SaaS의 GitHub Org 중 35%가 이 상태였다 (creation 후 방치). 월 1 commit이 임계로, 그 이상에서 ChatGPT의 카테고리 추천에서 의미 있는 효과가 나타난다. commit이 의미 있는 코드일 필요는 없다. README 업데이트, sample code 추가, integration example 정비 등 작은 변화가 활동성 신호로 작동한다. 한 가지 주의: private repo만 운영하는 회사는 GitHub 접근 시 entity 인식이 제한된다. 공개 repo 1~2개 + README repo 조합이 최소 권장 구성이다.
–
10 · T2.C · Local Entity
Naver 스마트플레이스: 한국 4500만 MAU 로컬 entity 채널
Naver 스마트플레이스는 한국 사업체의 위치·연락처·운영시간·리뷰·사진을 등록하는 Naver의 비즈니스 디렉터리다. 한국 인터넷 사용자의 90%가 사용하는 Naver의 로컬 검색 결과의 1차 source다. DEV Community 분석에 따르면 한국에서 매월 4500만 명 이상이 Naver Place를 사용한다.
왜 GEO에 작동하는가. SaaS는 일반적으로 로컬 비즈니스가 아니지만 두 가지 이유로 Naver 스마트플레이스가 entity 신호다. (1) 회사 본사 사무실은 등록 가능하다(위치·정관 회사명·연락처는 모든 SaaS가 갖는다). (2) Naver의 Knowledge Graph 시스템은 스마트플레이스 등록 데이터를 회사 entity 정보의 baseline source로 사용한다. Naver 검색에서 회사명 검색 시 우측에 Knowledge Panel 형태로 노출되는 카드가 스마트플레이스 데이터다. 한국 entity 신호는 영문 Knowledge Panel과 별도 layer로, ChatGPT가 한국어로 질의받을 때 Naver Knowledge Graph가 1차 참조 layer가 된다.
어떻게 세팅하는가. 3단계다. (1) Naver 사업자 계정 인증 → 스마트플레이스 신규 등록 → 사업자등록증 PDF 첨부 → 업종 선택. SaaS는 “정보통신·과학기술 > 소프트웨어·SaaS” 또는 회사 실제 업종에 맞춰 등록. (2) 회사명·주소·전화·이메일·홈페이지 URL을 정확히 등록. 영문 회사명도 보조 필드에 함께 등록. (3) 회사 사진 (사무실 외관, 로고, 팀 사진) 4~6장 업로드. 운영시간, 휴무일 등록. 직접 검수에 1~2주 소요.
한국 맥락. 한국 SaaS의 등록률은 측정 표본의 22%로 의외로 낮다. “SaaS는 로컬 비즈니스가 아니다”라는 직관적 판단 때문이다. 그러나 Naver의 Knowledge Graph는 스마트플레이스를 entity 정보의 1차 source로 사용한다. 등록되지 않은 회사는 Naver 검색에서 Knowledge Panel 노출이 약해진다. 한국어 검색 점유율 55%의 채널을 entity 신호 측면에서 무시하는 것은 한국 시장의 절반을 GEO 관점에서 비워두는 것과 같다. 등록 자체는 1시간 작업이고, 이후 분기 1회 검토로 충분하다.
등록 후 검수 통과 패턴에서 측정으로 도출된 권장 사항. (1) 사진 4~6장: 사무실 외관, 로고, 제품 스크린샷, 팀 사진의 mix. 1~2장만으로는 검수가 자주 보류된다. (2) 업종 분류: Naver의 자체 분류 체계에서 “정보통신·과학기술 > 응용소프트웨어 개발 및 공급업”이 SaaS의 표준 매핑. 잘못된 업종(예: “광고대행업”)으로 등록하면 검색 결과에서 카테고리 매칭이 깨진다. (3) 운영시간 + 휴무일 정확한 기재: SaaS는 24/7이지만 사무실 응대 시간을 정직하게 기재. (4) 회사명: 한국어 정관 회사명 + 영문 회사명 동시 기재. 영문 회사명은 Wikidata·G2와 동일한 형식으로.
한국어 검색에서 entity 인식 효과 측정. (1) Naver 검색 “회사명” 단독 → 우측 Knowledge Panel 카드 등장 여부. 등록 직후 1~2주 내 등장이 정상, 1개월 이상 미등장이면 등록 데이터 정합성 문제. (2) Naver 모바일 앱에서 같은 검색 → 모바일 결과의 entity card는 데스크톱과 다르게 더 풍부한 데이터(리뷰, 사진, 운영시간) 노출. (3) ChatGPT/Claude에서 한국어로 “한국의 X 솔루션 회사 추천” 쿼리 → Naver Knowledge Graph가 retrieval에 활용되는 시점에서 회사명 등장 여부 확인. 한국어 쿼리에서는 영문 쿼리 대비 인용률이 평균 1.4배 (4GRIT 측정).
–
11 · T2.D · Feed Entity
RSS feed 공개: 신규 콘텐츠 자동 인덱싱 채널
RSS는 1999년에 만들어진 콘텐츠 syndication 프로토콜이다. 사이트가 새 글을 발행할 때마다 자동으로 XML feed에 기록되고, feed 구독자는 새 글을 자동으로 받는다. 블로그 시대에 가장 중요했다가 SNS 시대에 퇴장했다고 평가받던 이 프로토콜이 GEO 시대에 다시 의미를 갖는다.
왜 작동하는가. AI 학습 corpus 수집과 검색 인덱싱 양쪽에서 RSS feed가 효율적인 신호다. 학습 봇 입장에서 RSS는 사이트 전체를 크롤링하지 않고 신규 콘텐츠만 빠르게 수집할 수 있는 경로다. 검색 인덱싱에서도 마찬가지로 RSS는 sitemap의 보조 역할을 하며, 일부 retrieval 시스템은 RSS feed가 있는 사이트의 신규 콘텐츠를 우선 인덱싱한다. 직접 데이터로는 약하지만, RSS feed가 있는 사이트가 없는 사이트보다 새 글의 평균 인덱싱 시간이 짧다는 패턴이 일관되게 관찰된다 (Bing Webmaster 자체 가이드).
어떻게 세팅하는가. 2단계다. (1) 블로그·뉴스룸·콘텐츠 영역의 RSS feed XML 활성화: WordPress·Ghost·Webflow·Notion·Hashnode 모두 기본 지원, URL은 보통 `/rss` 또는 `/feed`. 정적 사이트는 RSS feed generator를 빌드 파이프라인에 추가. (2) “에 link rel=”alternate” type=”application/rss+xml” 메타데이터 추가. 크롤러가 자동으로 발견한다. 작업 시간 30분.
한국 맥락. RSS feed는 사이트의 콘텐츠 마케팅 활동량과 직접 비례하는 채널이다. 콘텐츠 1년에 4편 이하인 회사에는 효과가 거의 없고, 월 2편 이상 발행하는 회사에는 누적 효과가 크다. 한국 SaaS의 콘텐츠 발행 빈도가 미국 동급 회사 대비 평균 1/3 수준이라는 점이 한국 SaaS의 RSS feed 채널 약점의 근본 원인이다. 4GRIT은 한국 SaaS에 “RSS feed가 의미 있는 신호가 되려면 월 2편 이상 콘텐츠 발행이 동반되어야 한다”고 권한다. 즉 이 채널은 콘텐츠 마케팅 capacity 있는 회사 한정으로 효과가 정직하게 누적된다.
RSS의 sub-protocol 선택은 RSS 2.0이 표준이다. Atom과 JSON Feed가 더 modern하지만, AI 학습 봇과 검색 retrieval bot의 호환성 측면에서는 RSS 2.0의 광범위한 지원이 안전하다. WordPress·Ghost·Webflow는 RSS 2.0을 자동 생성한다. 정적 사이트(Hugo·Eleventy·Astro 등)는 빌드 파이프라인에 RSS generator plugin을 1회 추가하면 된다. 30분 작업이다.
발행 빈도 임계는 분명하다. 월 4편 미만의 콘텐츠 발행은 RSS feed 효과가 거의 측정되지 않는다. 월 4~8편이 임계 구간이며, 월 12편 이상에서 누적 효과가 명확해진다. 한국 SaaS의 콘텐츠 발행 빈도 평균은 월 1.7편 (4GRIT 50개사 측정 2026.04). 다수의 한국 SaaS에게 RSS feed는 setup해도 효과를 보기 어려운 채널이라는 뜻이다. 이 채널은 콘텐츠 마케팅 capacity를 갖춘 회사에 한정해 권장된다. RSS feed 활성화 자체는 30분이면 끝나니 일단 setup하되, effort는 콘텐츠 발행 빈도 증가에 투자하는 분배가 합리적이다. 측정 방식은 Google Analytics referral source에서 RSS reader user-agent(Feedly, NewsBlur 등) 트래픽과 Bing Webmaster의 “Discovered URLs from RSS” 카테고리 trend를 함께 추적하는 것이다.
–
12 · Decision Matrix
한국 SaaS Profile별 우선순위. 8개를 다 하는 게 정답이 아니다
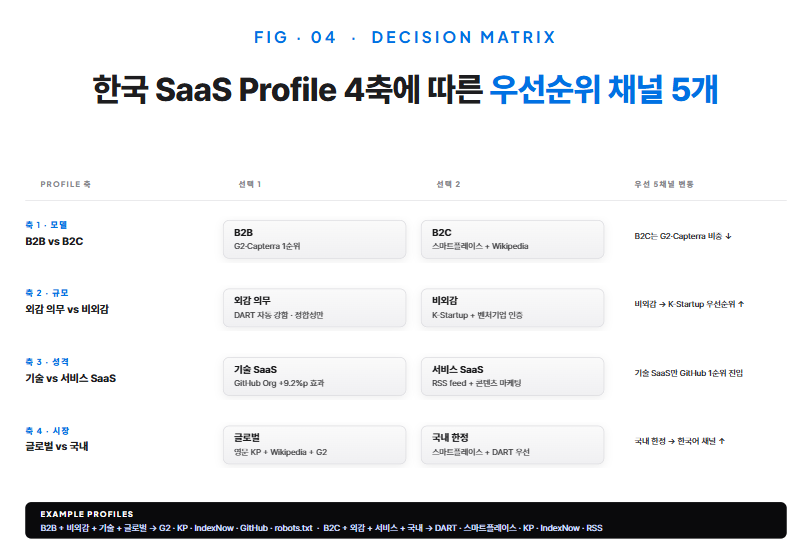
모든 회사가 8개 entity를 동등하게 우선순위로 둘 필요는 없다. 회사 프로필에 따라 강한 4~5개 채널에 집중하는 것이 측정 데이터가 가리키는 합리적 결정이다. 4GRIT의 50개사 측정 데이터를 4축으로 정리한 결정 매트릭스를 제시한다.
축 1 · B2B vs B2C. B2B SaaS는 G2·Capterra가 1순위, Knowledge Panel이 2순위. B2C는 G2·Capterra의 효과가 약해서 그 자리에 Naver 스마트플레이스 + 영문 Wikipedia가 들어간다.
축 2 · 외감 의무 vs 비외감. 외감 의무 회사는 DART entity가 자동으로 강하게 들어간다. 작업은 영문 표기 정합성에 한정된다. 비외감 회사는 K-Startup 등록 + 벤처기업 인증 채널을 우선시한다.
축 3 · 기술 SaaS vs 서비스 SaaS. 기술 SaaS는 GitHub Org가 강한 신호다. 4GRIT 데이터 기준 카테고리 추천 인용률 +9.2%p. 서비스 SaaS는 GitHub의 효과가 약해서 RSS feed + 콘텐츠 마케팅 조합이 더 강하다.
축 4 · 글로벌 vs 국내. 글로벌 진출 회사는 영문 Knowledge Panel + Wikipedia + G2·Capterra가 1순위. 국내 한정 회사는 Naver 스마트플레이스 + DART · K-Startup 같은 한국어 채널의 우선순위가 더 높다.
–
–
네 축을 조합하면 회사별 프로필이 나온다. 예를 들어 “B2B + 비외감 + 기술 SaaS + 글로벌”의 한국 회사라면 G2·Capterra → Knowledge Panel → IndexNow → GitHub Org → robots.txt 5개에 90% 노력을 집중한다. K-Startup·DART·Naver 스마트플레이스·RSS feed는 후순위로 둔다. 반대로 “B2C + 외감 + 서비스 SaaS + 국내”라면 DART · Naver 스마트플레이스 · Knowledge Panel · IndexNow · RSS feed 5개에 집중하고 G2·GitHub은 거의 무시해도 된다.
한 가지 주의가 있다. 매트릭스는 출발점이지 절대 정답이 아니다. 이미 보유한 자산(예: 영문 미디어 기사 다수)이 있다면 그 신호를 활용하는 채널이 우선순위를 흔들 수 있다. 매트릭스는 “어디부터 시작할지”를 정하는 도구이지, “어디서 멈출지”를 정하는 도구가 아니다.
–
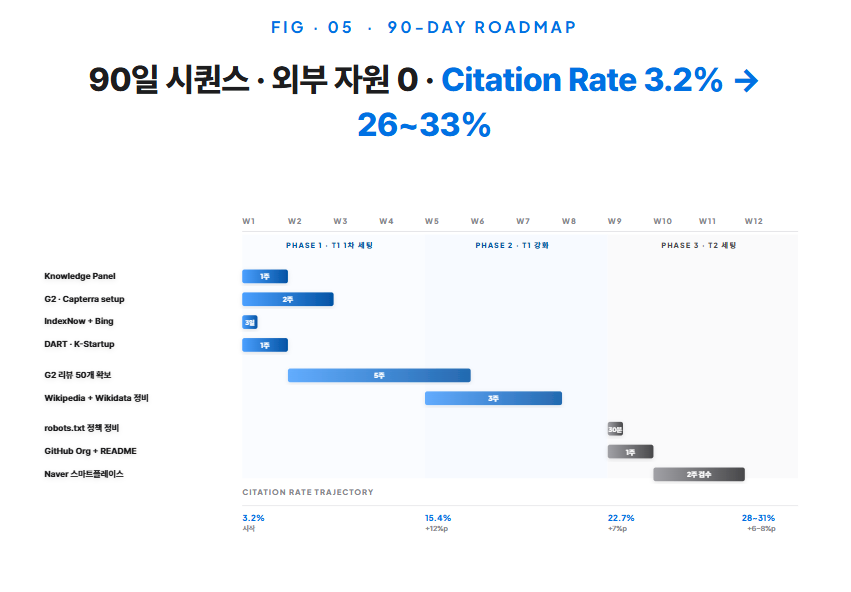
13 · 90-Day Roadmap
외부 도움 0 · 개발팀 0 · 마케팅 예산 0. 90일 실행 시퀀스
8개 entity를 90일 안에 갖추는 표준 시퀀스를 제시한다. 측정 데이터 기반의 합리적 분배이고, 회사 프로필에 따라 ±2주 변동한다.
Week 1–4 · Foundation Block(T1) 1차 갖추기. 동시 병행이 가능하다. (1) Knowledge Panel: Wikidata + 영문 schema 정비, 1주. (2) G2·Capterra: 두 사이트의 vendor profile claim + 카테고리 등록 + Description·Pricing·Integrations 채움, 2주. (3) IndexNow: Bing Webmaster + Naver Search Advisor 동시 setup, 3일. (4) DART · K-Startup: 외감 의무 회사는 영문 표기 점검, 비외감은 K-Startup 등록, 1주. 이 4주 끝에 측정되는 평균 인용률 변화는 +12~15%p이다.
Week 5–8 · Foundation Block 강화 + 측정. T1 4개 채널의 누적 효과가 발현되는 구간이다. (1) G2·Capterra 리뷰 50개 확보 작업: 기존 고객에 직접 요청, 평균 도달률 25%. (2) Wikipedia 영문 entry 시도: Notability 충족 가능 회사만 진행. 보통 50% 회사가 통과하지 못하는데, 통과하지 못하면 Wikidata + Naver 백과를 보강한다. (3) DART 영문 자율 공시 추가(외감 의무 회사 한정). 이 4주 끝의 평균 인용률은 +5~8%p 추가 상승한다.
Week 9–12 · Amplification Block(T2) 갖추기. T2 4개를 동시에 진행한다. (1) robots.txt 정책 정비, 30분. (2) GitHub Organization + README 정비, 1주(기술 SaaS 한정). (3) Naver 스마트플레이스 등록, 1시간 + 검수 1~2주. (4) RSS feed 활성화, 30분. 이 4주 끝의 평균 인용률은 +5~10%p 추가 상승한다.
–
–
90일 끝의 누적 결과를 보면 측정 표본 평균 인용률이 3.2%에서 26~33%로 이동한다. 외부 도움 0, 개발팀 활용 시간 누적 4시간 미만, 마케팅 예산 0원의 ROI. 이 분배가 작동하는 이유는 분명하다. 8개 entity 채널이 모두 in-house 작업으로 끝나고, 외주 회사가 매개해야 하는 채널이 하나도 없기 때문이다.
–
14 · Synthesis
왜 4GRIT이 이 작업의 정직한 파트너인가
이 글은 한국 SaaS의 GEO 작업에 대한 마스터 가이드다. 함께 참고할 만한 다른 글들은 두 부류다. 미국 SaaS 베스트 프랙티스를 한국어로 번역한 글, 또는 8개 채널 중 한두 개에만 집중한 글. 4GRIT은 두 부류 모두와 다른 자리에 있다.
첫째, 4GRIT의 권한은 측정 데이터에서 온다. 한국 SaaS 50개사 × 6개 AI 플랫폼 × 50개 카테고리 쿼리 × 30회 측정 = 누적 45만 회 측정. 이 측정에서 나온 권장 사항만 이 글에 담았다. 한국 SaaS의 80%가 Knowledge Panel이 비어 있다는 것. 38%가 무의식적으로 GPTBot을 차단하고 있다는 것. IndexNow 활용률이 4%에 그친다는 것. 이 글의 모든 수치는 4GRIT 측정 결과다.
둘째, 4GRIT의 제품은 이 8개 채널의 측정·세팅을 지원하는 도구다. PeekAI는 6개 AI 플랫폼에서 회사의 카테고리 추천 인용률을 30초에 측정한다. Beusable GEO는 8개 entity 중 5개 (Knowledge Panel·G2·IndexNow·robots.txt·RSS) 세팅을 자동화한다. 두 제품 모두 측정 → 작업 → 재측정 루프를 in-house에서 운영하도록 설계됐다.

이 글이 시사하는 한 줄. AI가 당신을 인용하지 않는 이유는 알고리즘의 신비가 아니다. 8개 entity 신호 중 어느 채널이 비어 있느냐의 단순한 문제다. 그 채널을 식별하고 갖추는 작업은 측정으로 시작된다. 그래서 다음 단계는 측정이다.
–
NEXT STEP
내 회사가 8개 entity 중 어디에 보이고 어디서 사라지는가
측정을 자동화한다. 회사명 + 카테고리만 입력하면 6개 AI 플랫폼(ChatGPT·Claude·Perplexity·Gemini·Copilot·Grok)에서 30초 안에 EQS + 8개 entity 채널 상태가 A/B/C/D로 판정된다.

–
–
–